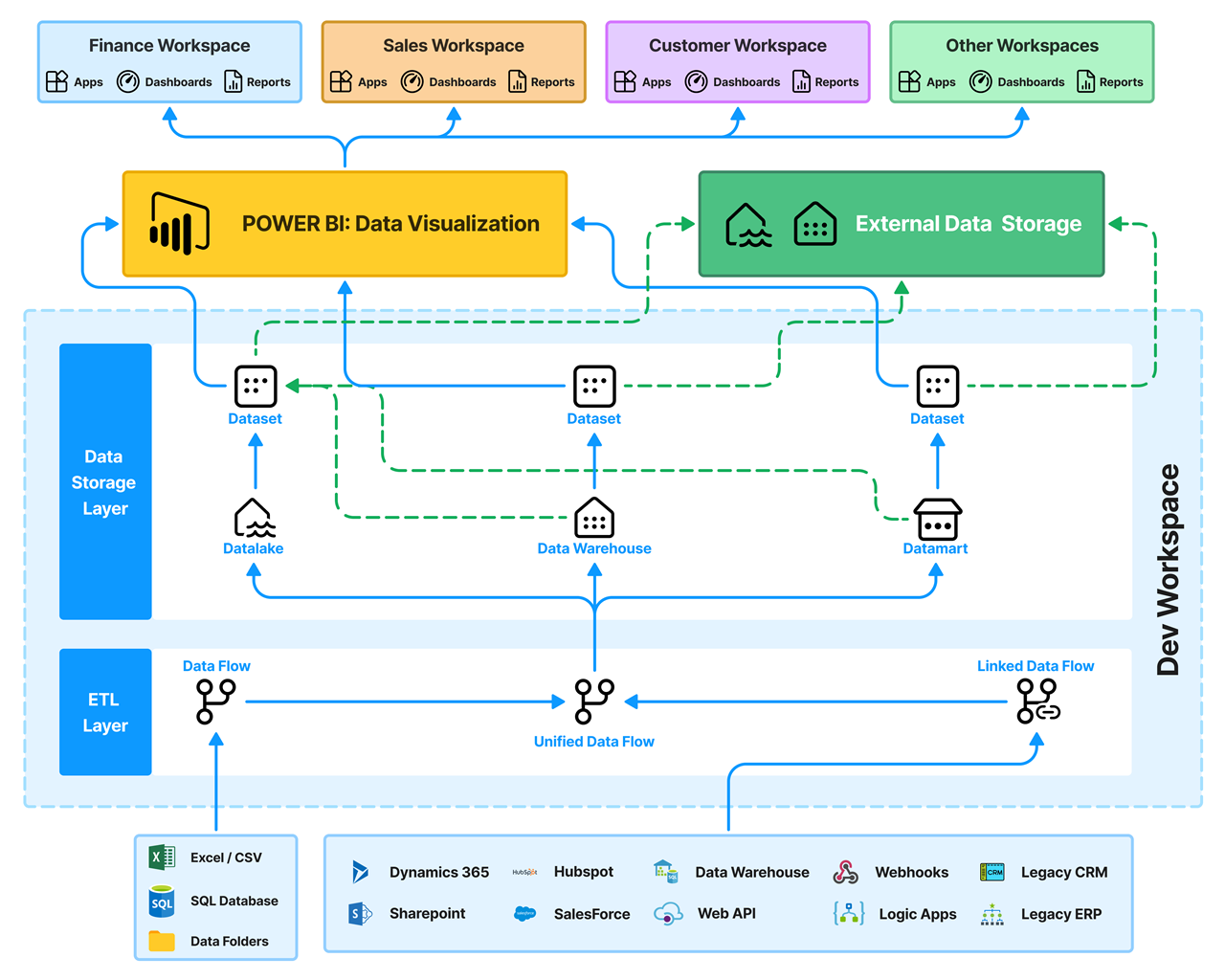
ETL, which stands for Extract, Transform, Load, is a critical process for moving data from disparate sources into a centralized data warehouse or data lake. This transformed data is then used for various analytical purposes. Let's delve into the steps involved in setting up an ETL data pipeline.
Understanding the ETL Process
Before diving into the setup, it's essential to grasp the three core stages of ETL:
- Extract: This involves fetching data from various sources such as databases, files, APIs, or cloud-based platforms.
- Transform: Data is cleaned, standardized, aggregated, and manipulated to meet specific requirements. This might involve data cleansing, formatting, calculations, and data enrichment.
- Load: The transformed data is loaded into a target system, typically a data warehouse or data lake.
An ETL (Extract, Transform, Load) data pipeline is essentially a conduit for moving data from its original source to a destination system, often a data warehouse or data lake, where it can be analyzed. Let's break down the key components:
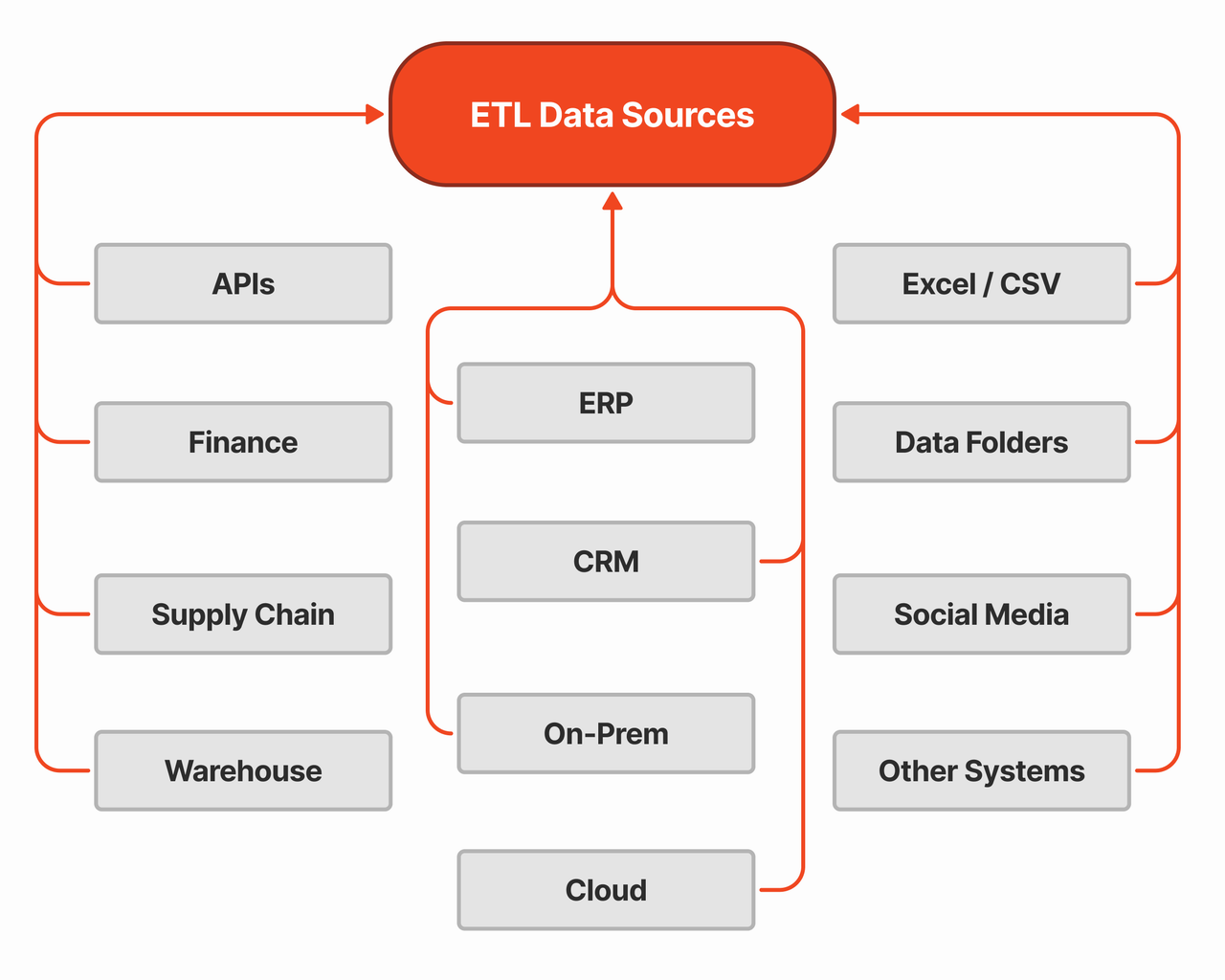
These are the origin points of the data. They can be diverse and complex, ranging from:
- Relational Databases: Traditional systems like Oracle, SQL Server, MySQL.
- Flat Files: CSV, Excel, or text-based files.
- NoSQL Databases: MongoDB, Cassandra, etc.
- Cloud-Based Storage: AWS S3, Azure Blob Storage, Google Cloud Storage.
- APIs: Web services providing data in JSON or XML format.
- Real-time Feeds: Data streams from sensors, social media, or financial markets.
Key considerations when dealing with source systems:
- Data Format: Understanding the structure of data in different formats.
- Data Quality: Assessing data accuracy, completeness, and consistency.
- Data Volume: Determining the amount of data to be extracted.
- Data Extraction Methods: Choosing appropriate methods based on data source (e.g., SQL queries, API calls, file transfers).
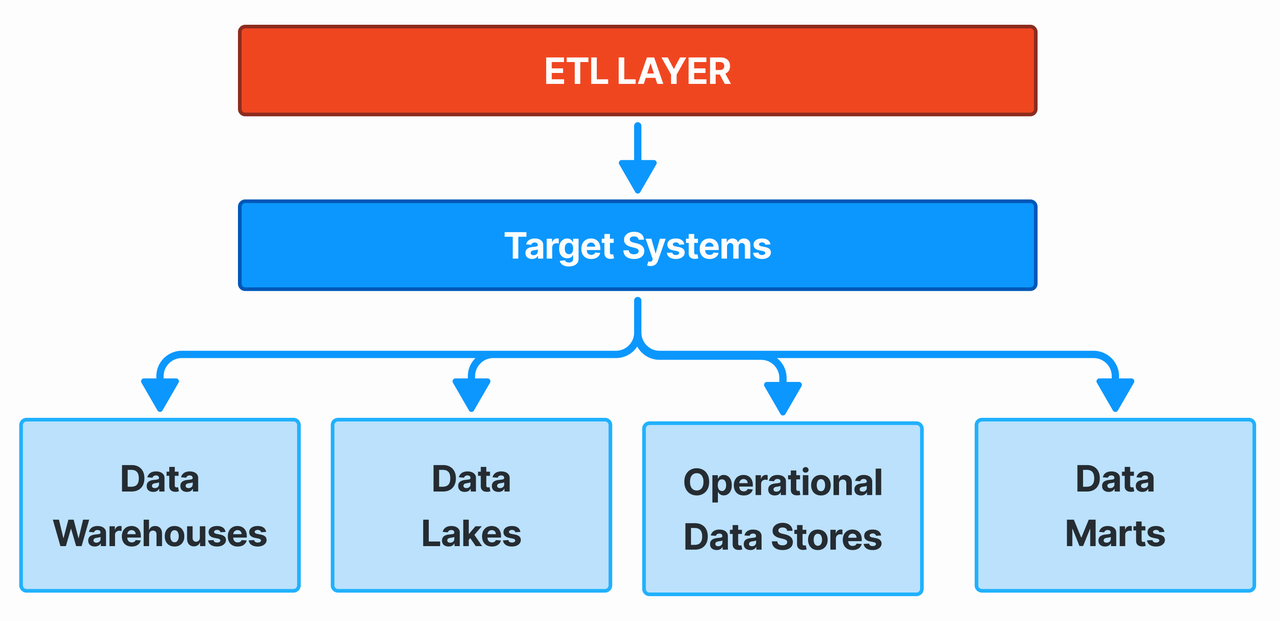
These are the destinations for the transformed data. Common target systems include:
- Data Warehouses: Optimized for analytical workloads (e.g., Teradata, Snowflake, Redshift).
- Data Lakes: Scalable storage for raw data (e.g., Amazon S3, Azure Data Lake Storage).
- Operational Data Stores (ODS): For short-term data storage and processing.
- Data Marts: Subsets of data for specific business units.
Key considerations for target systems:
- Data Model: Designing the target data structure to meet analytical needs.
- Data Loading Methods: Selecting efficient loading techniques (e.g., bulk load, incremental load).
- Performance: Ensuring optimal query performance and response times.
- Data Governance: Implementing security and access controls.
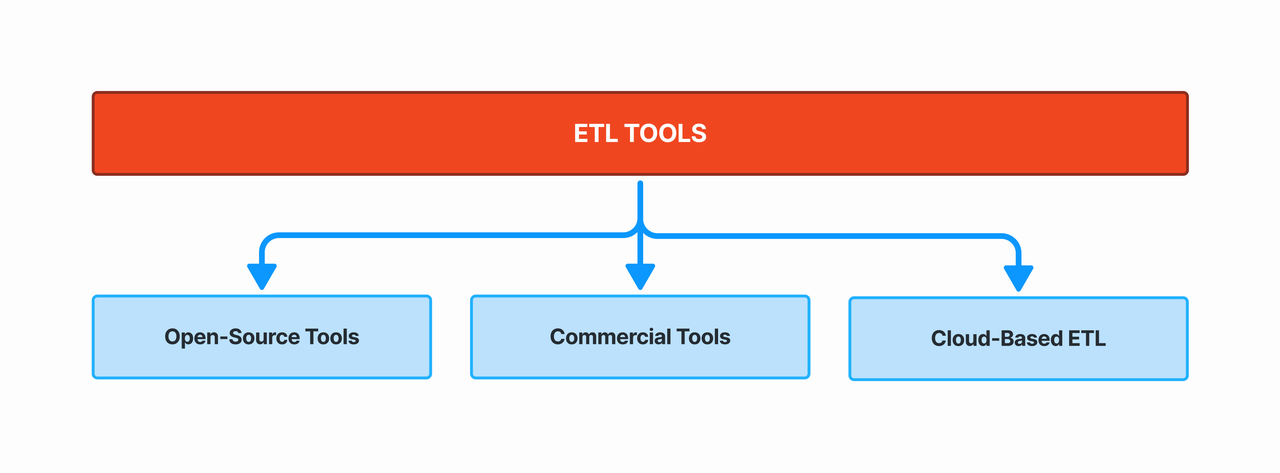
These software applications facilitate the ETL process, automating tasks and improving efficiency. The landscape is fast changing. Currently popular ETL tools include:
- Open-Source Tools: Apache Airflow, Apache NiFi, Talend Open Studio.
- Commercial Tools: Informatica, IBM DataStage, Oracle Data Integrator.
- Cloud-Based ETL: AWS Glue, Fabric Data Factory, Google Cloud Dataflow.
Key factors in choosing an ETL tool:
- Scalability: Ability to handle increasing data volumes and complexity.
- Features: Support for various data sources, transformations, and target systems.
- Integration: Compatibility with existing systems and tools.
- Ease of Use: User-friendly interface and development environment.
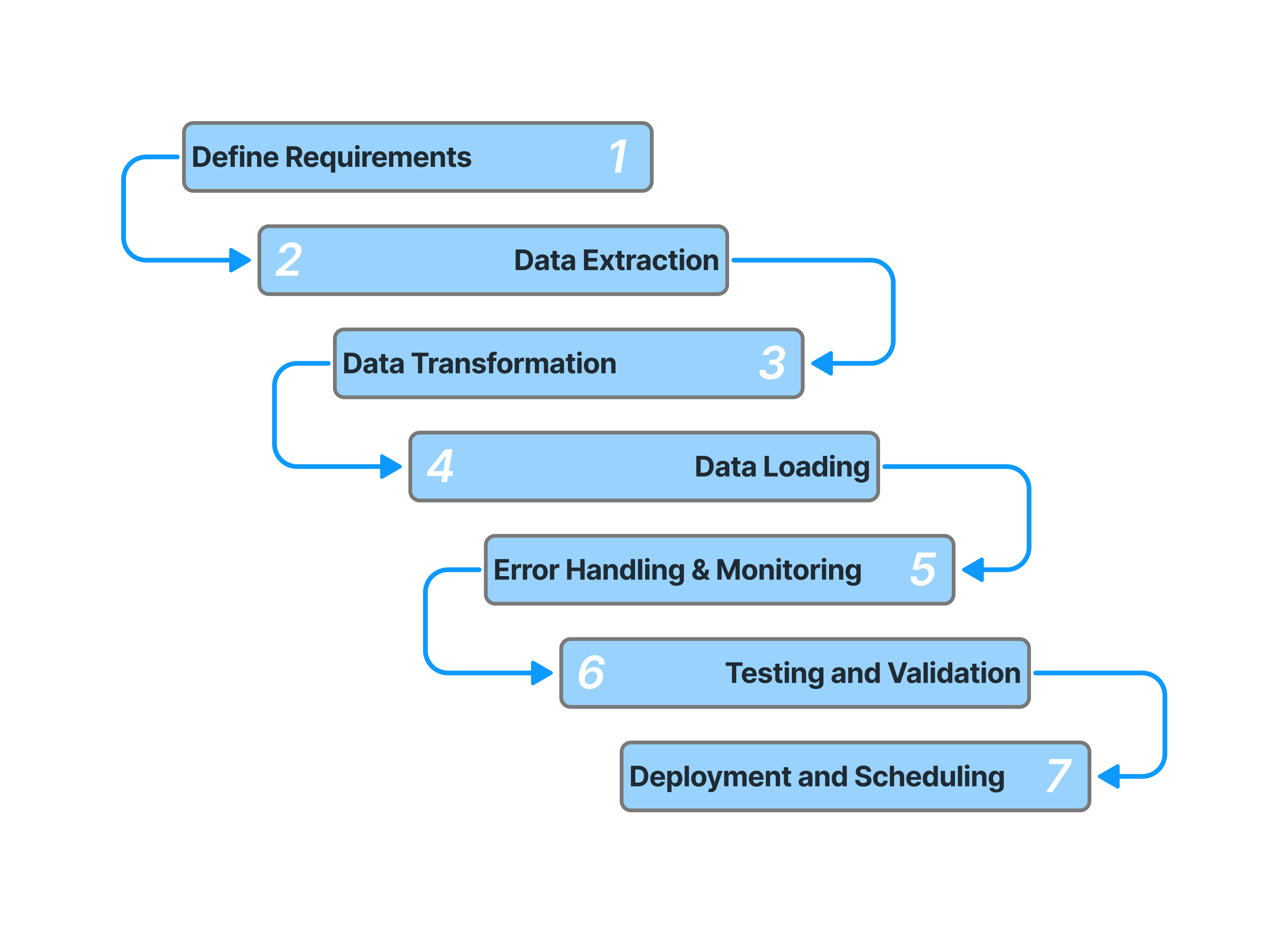
A well-designed ETL pipeline effectively connects source systems, target systems, and ETL tools. Key considerations include:
- Data Mapping: Defining how data elements from sources will be mapped to target structures.
- Data Extraction: Defining the logic and method for data extraction from disparate systems
- Data Cleansing: Removing or correcting data inconsistencies and errors.
- Data Transformation: Applying business rules and calculations to create derived data.
- Data Loading: Transferring transformed data to the target system efficiently.
- Error Handling: Implementing mechanisms to handle exceptions and failures.
- Monitoring and Logging: Tracking pipeline performance and identifying issues.
By carefully selecting and integrating source systems, target systems, and ETL tools, organizations can build robust and efficient data pipelines to support data-driven decision-making.