All about ETL PipelinesExtract, transform & load (ETL) data pipelines are the processes to move and transform data from different sources to a single data storage system for analysis. The pipeline fetches the data from multiple sources, transforms it to a form which can be used and stored in databases or data warehouses. Through this automated process, the businesses are spared by ensuring data quality, consistency and accessibility, so they can make informed decisions, fast, with the right data, which most often is organized data.
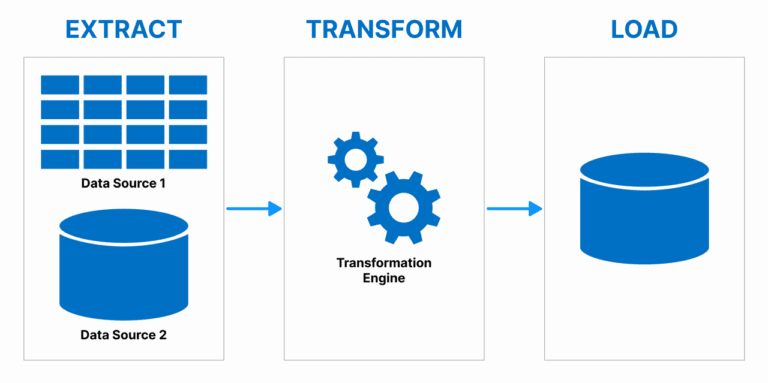
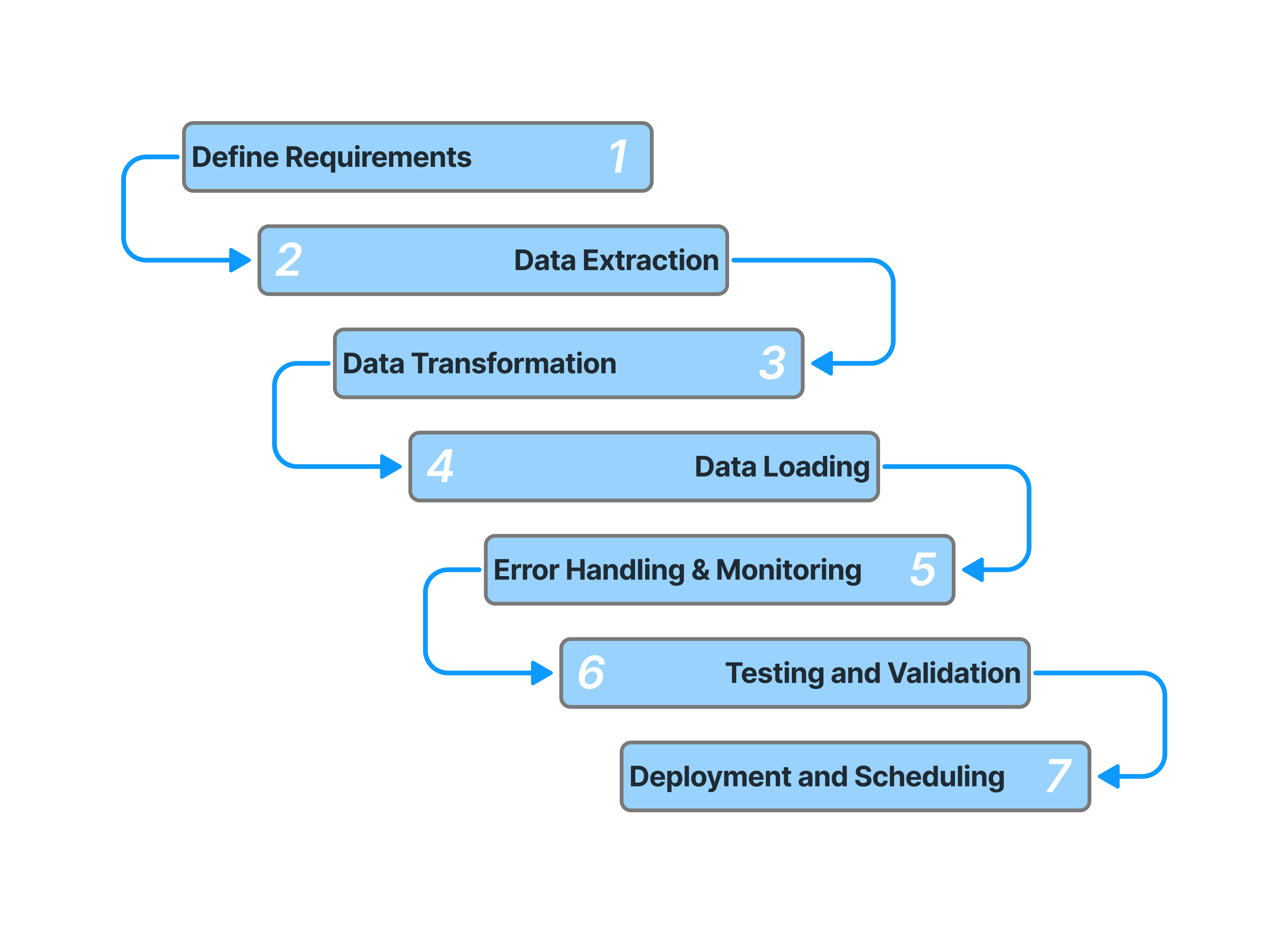
Setting Up ETL PipelinesETL data related to pipeline consists in identify a process to extract data from various sources, format it as required for example by a data warehouse or storage system, without disregarding transformations that are essential to decipher the data. The strategy consists of choosing the right tools and developing data flows and validating and cleaning data. Integrating data into business applications can be a tedious, time consuming process, especially with inconsistent data sources. Automated workflow for this process enables businesses to streamline data integration, keep data more consistent, and provide trusted, clean data into business applications for analysis and decision making.
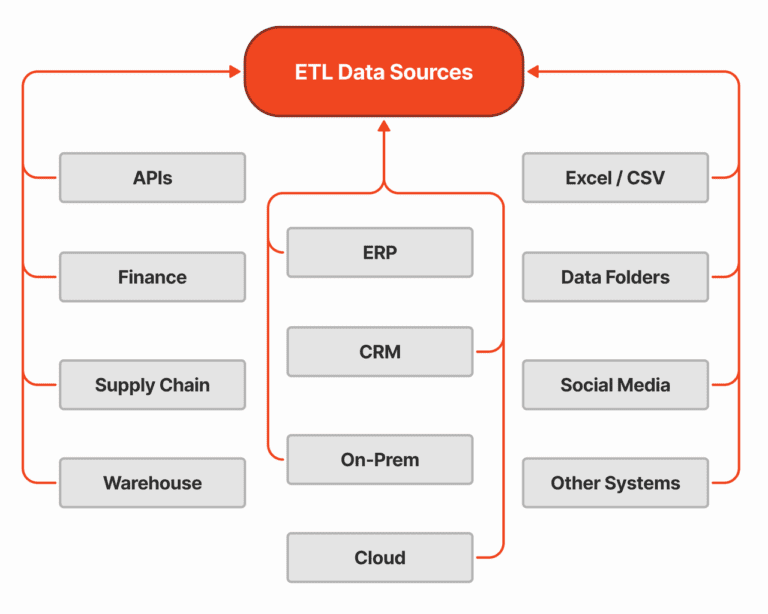
Sources for ETL PipelinesETL pipelines use data sources as those different sources which serve to data extract for further processing. Databases, cloud storage, APIs, spreadsheets, real time streaming services are just some of these. ETL pipelines allow data from various sources to be connected ensuring complete data integration to ensure the business collects, transforms, and aggregates data from various points, ensuring consistency and accuracy for analysis and reporting throughout the organization.

ETL & Data Quality IssuesSimilar to that, ETL pipelines are ubiquitous in transforming and connecting data, but may suffer from data quality issues such as inconsistencies, missing values, duplicates or inaccurate data during extraction, transformation or load stage. And these issues could affect the reliability and accuracy of insights we derive from the data. Therefore, ETL work flows are to be executed with data validation, data cleansing and monitoring processes to have high quality outcomes and also maintain data integrity and make accurate decisions about data.
Governance & Regulatory ImpactData is governed for the availability, usability, integrity, and security of data in an organization. It guarantees that data in line with GDPR and other regulations and keeping policies on data quality, privacy, and the accountability. Regulatory impact is an examination of the way legal requirements impact data management practices that urge businesses to protect sensitive data, decrease risk, and avoid penalties. Trust, compliance and the ability to make data driven decisions all depend on effective data governance in a regulated environment.
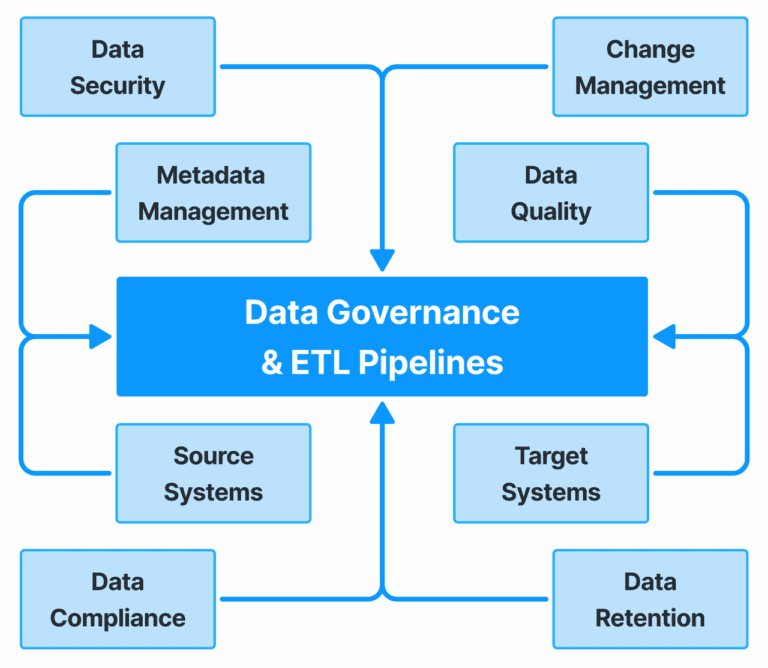

Governance & Access HierarchyData governance and access hierarchy function together to secure and efficiently manage the data in an organization. Data Governance is set of policies for data quality, privacy and compliance, and Access hierarchy dictates what users are allowed to view, modify or analyze data. However, implementing a logical access hierarchy will help businesses protect sensitive information, maintain data integrity and let the right people access the data they need.
Our team of Power Bi experts will work closely with you to build customized dashboards and scoreboards that provide clear, concise insights at a glance. With our expertise, you can unlock the full potential of your data, identify key trends, and discover actionable next steps that drive business growth. Don't let valuable opportunities slip through your fingers - partner with GainOps today for unparalleled data-driven success!
GainOps has helped these companies learn more about what's happening inside their own operations, and we've been there to help them with: